
Corpus numériques : enjeux de délimitation, d’archivage et d’analyse
1Dans sa signification contemporaine, le terme corpus, renvoie principalement au champ scientifique et désigne l’assemblage, si possible exhaustif, de l’ensemble des documents relevant d’un genre, d’un auteur ou d’une thématique donnée en vue de leur analyse. Il faut donc un principe qui permette de repérer et d’assembler des documents ou textes comme le genre, l’auteur, l’entrée thématique, la période. L’usage du mot corpus s’est beaucoup développé dans le champ de la linguistique quand il est devenu possible d’appliquer des algorithmes à des corpus de textes, jusqu’à l’émergence même d’une sous-discipline, la linguistique de corpus (Habert, Nazarenko et Salem, 1997) avec ses méthodes de recherche comme la lexicométrie, la statistique textuelle, la textométrie ou la fouille de texte, pour ne citer qu’une partie des termes utilisés pour qualifier ces ensembles de méthodes.
2L’adjonction du qualificatif numérique au terme corpus renvoie à deux entités différentes : d’une part aux corpus numérisés, des ensembles de textes imprimés transformés en objets numériques, et d’autre part aux corpus nativement numériques, produits et publiés dans l’espace numérique (Musiani et Schafer, 2017). Je me concentrerai dans cet article sur les corpus nativement numériques car ils bousculent nos catégories traditionnelles : les caractéristiques réticulaires, ouvertes et multimédias des documents transforment les questionnements sur la constitution, l’archivage et l’analyse de ces corpus.
3Je reviendrai d’abord sur le tournant de l’internet et du web, en soulignant les spécificités de l’écriture numérique, avant d’envisager leurs conséquences sur les corpus en termes de constitution, d’archivage et d’analyse. Je m’appuierai sur deux recherches que j’ai menées pour illustrer mon propos : l’une sur le réseau des écrivains en ligne (Beaudouin, 2012), l’autre sur les historiens amateurs qui font revivre la mémoire de la Grande Guerre en ligne (Beaudouin, Chevallier et Maurel, 2018).
De la statistique textuelle aux humanités numériques
4Si aujourd’hui la distinction entre corpus numérisés et corpus nativement numériques s’est imposée, la stabilisation du vocabulaire a pris un certain temps.
5Les premiers corpus numériques, souvent désignés comme des corpus électroniques, correspondaient à des ensembles de textes imprimés soumis à une opération de traduction dans l’espace électronique, la numérisation. Cette dernière consiste à produire une image numérique du texte, elle-même soumise le plus souvent à des procédures de reconnaissance de caractères, pour transformer l’image du texte en paragraphes et séquences de mots. Avec l’essor de l’informatique, les possibilités offertes par la numérisation des textes ont suscité un vif intérêt. En France, dès la fin des années 1950, le projet de Trésor de la Langue Française a fortement soutenu les ambitions de numérisation. En effet, ce dictionnaire de langue, en rupture avec la tradition lexicographique, devait s’appuyer exclusivement sur des citations attestées dans des corpus pour illustrer les articles, alors que jusque-là les exemples utilisés étaient conçus par les lexicographes, « en chambre ». La base Frantext a ainsi peu à peu assemblé des textes numérisés du canon littéraire complétés par des textes techniques, où ont été puisés les exemples du dictionnaire. Cette base a également servi de ressource essentielle pour les premiers travaux informatisés sur la littérature.
6Charles Muller, pionnier dans les traitements lexicographiques de corpus littéraires numérisés fait en effet remonter au colloque du CNRS organisé en 1957 à Strasbourg « Lexicologie et lexicographie françaises et romanes. Orientations et exigences actuelles » l’origine du projet de Trésor de la langue française, piloté par Paul Imbs (Muller, 1993). Il souligne le rôle de Bernard Quemada, « jeune collègue de Besançon [qui] révéla l’entrée en jeu des machines », au travers d’une communication intitulée « La technique des inventaires mécanographiques ». A cette époque on parle de moyens mécanographiques ou électroniques (Monfrin, 1963).
7Entre Besançon et Strasbourg, se met en place une dynamique active autour de Bernard Quemada, pour faire usage de ces corpus et de ces moyens mécanographiques. Charles Muller est le premier chercheur à utiliser ces techniques pour les appliquer au corpus des pièces de théâtre de Corneille (36 pièces), transformées en armoires de fiches perforées lisibles par la machine (Muller, 1967). Il met en place les principes de la statistique lexicale : des indicateurs pour évaluer la longueur des mots, la richesse lexicale et son évolution dans le temps, ou pour identifier le vocabulaire spécifique d’un texte (Muller, 1992). Dans cette période d’effervescence autour des textes informatisés, de nombreux chercheurs s’attellent à exploiter les corpus numérisés comme Charles Bernet et Etienne Brunet, pour ne citer que quelques exemples (Bernet, 1983 ; Brunet, 1989). Ces travaux font écho à une tradition anglo-saxonne portée par des revues et des conférences, comme Literary and Linguistics Computing ou Computers and the Humanities (Hockey, 2004). Les outils de traitement automatique du langage (phonétiseurs, analyseur morpho-syntaxiques, réseaux sémantiques) sont associés à des outils mathématiques et statistiques pour révéler des phénomènes sur les textes. La stylométrie et en particulier l’attribution d’auteur deviennent des sujets d’intérêt (Holmes, 1994). Renverser les hiérarchies, remettre en question les autorités naturelles garantit en effet l’attention du grand public. C’est ainsi que les Labbé ont pensé avoir démontré que Corneille avait écrit les comédies de Molière car elles étaient statistiquement proches de deux comédies de Corneille (Labbé et Labbé, 2001). S’en est suivi une intense controverse, alimentée par les médias, même si très tôt des chercheurs du domaine ont montré les limites de l’approche (Bernet, 2009 ; Brunet, 2011 ; Cafiero et Camps, 2019). Cette attention à la mesure du style est encore active et présente dans les communautés scientifiques relevant du domaine des Digital Humanities, et passionne surtout des informaticiens. Elle s’appuie sur des textes littéraires avec une vision plus englobante qui ne se limite pas au canon. Les méthodes deviennent de plus en plus sophistiquées, avec la mobilisation des techniques d’apprentissage machine (machine learning), mais le fond des questionnements a peu changé. Tout comme la sociologie qui distingue les approches quantitatives (enquêtes) et qualitatives (entretiens, observation ethnographique), dans le domaine de l’étude des textes, en reprenant les termes de Moretti, on distingue distant reading et close reading (Moretti, 2013).
8Cependant le domaine des Humanities Computing connaît des remous importants à partir des années 2000, et c’est à partir de 2006 que peu à peu le terme de Digital Humanities s’impose. Ce changement de terminologie tient à des changements épistémologiques majeurs, qu’a analysés Svensson (Svensson, 2009). Si les Humanities Computing était orientées principalement vers la constitution et l’analyse de corpus textuels, le champ des Digital Humanities va couvrir des dimensions différentes. Au début des années 2010, Svensson, distingue, dans le champ des Digital Humanities, cinq manières pour les sciences humaines d’envisager les technologies de l’information : soit comme simple outil (dans la lignée de ce qui se faisait avec les Humanities Computing), soit comme objet de recherche (analyser les pratiques numériques elles-mêmes), soit comme moyen d’expression (de nouveaux lieux de prise de parole pour les chercheurs émergent comme les blogs, réseaux sociaux…), soit dans une perspective de laboratoire d’expérimentation (art-science…) ou enfin dans une perspective militante (Svensson, 2010). Il ne s’agit plus seulement de constituer et d’analyser des corpus, mais de prendre en compte de façon plus globale les relations entre sciences humaines et technologies. Et évidemment le tournant numérique que représente la diffusion d’internet est au cœur de cette transformation.
Le tournant de l’internet et du web
9Internet et le web sont à l’origine d’importantes transformations et de l’émergence d’une nouvelle catégorie de corpus : les nouveaux dispositifs socio-techniques d’écriture ont favorisé les formes d’auto-publication et donc la possibilité de constituer des corpus nativement numériques aux propriétés singulières.
Internet : de la conversation par écrit à l’émergence de genres
10Revenir sur la généalogie de l’internet nous permet de mieux identifier les singularités de ces formes d’écriture en ligne. L’innovation la plus marquante apportée par internet tient au fait que pour la première fois une technologie permet d’organiser et de soutenir la conversation à plusieurs et donc la vie de petits groupes distribués dans le temps et l’espace. Jusqu’à l’arrivée d’internet, une série d’innovations avait permis l’émergence de techniques d’une part pour la relation à deux (le modèle de la conversation) : la lettre, le télégramme, le téléphone et d’autre part pour la relation d’un émetteur vers un public (le modèle des médias) : imprimerie, presse, radio, télévision… On avait d’un côté des supports pour la relation à deux à distance ; de l’autre des médias largement asymétriques d’un émetteur vers un public de masse. Internet apporte une innovation majeure dans l’entre-deux, entre l’interaction à deux et la diffusion unilatérale : il offre aux groupes la possibilité de discuter à plusieurs sans être contraints à une coprésence spatiale et temporelle. Les forums, les listes de discussions, les Internet Relay Chat sont les premiers dispositifs qui soutiennent cette vie communautaire, relayés ensuite par les groupes Facebook, les messageries comme Messenger et aujourd’hui par les groupes Discord ou WhatsApp.
11Ces nouvelles formes de conversation se déroulent par écrit et ouvrent à une mutation anthropologique majeure : l’usage généralisé de l’écriture pour la conversation ordinaire. Pour prendre la mesure de cette transformation, il nous faut à présent nous livrer à un exercice de pensée complexe pour se situer dans un passé finalement assez récent où internet et les téléphones portables étaient des objets inconnus et les formes de conversation par écrit quasi-inexistantes.
12Cet essor de la conversation par écrit s’est accompagné d’un autre phénomène notable : le déploiement des formes d’auto-publication en ligne, qui permettent à tout un chacun de s’exprimer (Allard et Vandenberghe, 2003 ; Beaudouin, Fleury et Pasquier, 2004). Ces espaces de présentation de soi, qui sont autant de ressources pour entrer en relation, sont des lieux de production d’écritures qui s’inscrivent dans des plateformes. Celles-ci connaissent des vagues d’innovation majeures : pages personnelles, blog, compte Facebook, chaine YouTube, compte Instagram, compte TikTok... Equiper la vie des collectifs en ligne tel a été le point le plus marquant de la révolution internet tout en donnant à chacun et chacune la possibilité d’être « auteur ».
13Ces transformations passent par l’écrit, un écrit avec mémoire, qui laisse des traces et peut donc faire l’objet d’archivage et de traitements ultérieurs. On assiste donc à un brouillage des frontières entre publication et conversation (Beaudouin, 2002). Si l’écrit était autrefois réservé à la publication et à l’échange épistolaire et l’oral à la conversation, avec internet, l’écrit, en devenant le support de la conversation ordinaire, déploie ses propres spécificités. Le monde numérique refabrique un continuum qui va de la publication à la conversation. Ainsi la conversation change de régime et entre dans celui des écrits qui laissent des traces. Cela nous invite à croiser des traditions d’analyse distinctes : celles qui traitent des textes et celles qui traitent de la conversation, comme l’analyse conversationnelle en ethnométhodologie.
14La perspective que j’adopte consiste à étudier la constitution de genres à l’ère numérique. Le genre est une forme de convention entre les auteur·rices et les lecteur·rices, entre les producteur·rices et les récepteur·rices, qui définit un cadre de production et réception. Le genre se situe à la frontière comme objet de la linguistique et de la sociologie, comme pratique de la langue et pratique sociale (Rastier, 1989). Comment se stabilisent des formes d’écriture comme pratiques sociales dans un cadre collectif ? Cette perspective conduit à enquêter dans deux directions : celle de la compréhension des mondes sociaux dans lesquels s’inscrivent ces pratiques d’écriture ; celle de l’analyse de ces formes d’écriture. Quand on travaille sur les corpus nativement numériques, on se situe à distance des canons littéraires, puisqu’on entre dans le monde des pratiques d’écriture en amateur, aux frontières des mondes professionnels et que l’on porte attention aux formes d’écriture ordinaires.
15J’entends écriture au sens large : cela concerne les textes, mais également les publications multimédia, les vidéos, ainsi que les structures qui permettent d’assembler les écritures (un site, une chaine, un compte) qu’on peut apparenter à la notion de recueil.
Traits communs aux écritures numériques
16L’écriture en ligne se caractérise par des formes peu stabilisées qui se transforment au rythme de l’innovation du secteur des technologies numériques. Il est frappant de constater à quel point les pratiques d’écriture en ligne sont rapidement marquées par le sceau de l’obsolescence. La consultation d’archives de sites personnels ou de blogs témoigne de cet effet de vieillissement accéléré, imposé par l’industrie. Pour les jeunes générations, le cadre de l’écriture de Facebook est déjà considéré comme obsolète. De fait, l’écriture numérique, parce qu’elle s’inscrit dans des infrastructures soumises au rythme intense de l’innovation, impose régulièrement des épreuves à ses utilisateur·ices. Par exemple, dans une enquête menée auprès d’auteur·ices de sites personnels, ces dernier.es soulignent le coût (en termes de compétences principalement) lié au changement de plateformes et de formats, qui justifie parfois l’abandon de la pratique (Licoppe et Beaudouin, 2002). Le glissement d’un format à l’autre ne va pas de soi. Quand les auteur·ices se déplacent de Facebook à Instagram, ce sont de nouvelles pratiques d’écriture qui se constituent, qui donnent la primauté à l’image, et qui conduisent à inventer de nouvelles formes de textes. De même pour les auteur·ices passer de la plateforme YouTube, avec des vidéos en mode paysage dont la durée se compte en minutes, aux vidéos verticales de TikTok de durée très courte invite à repenser les modes d’écriture. Quels sont cependant les éléments de stabilité dans ces formes d’écriture ?
17Premièrement, c’est une écriture qui s’inscrit dans un dispositif sociotechnique qui agit comme une contrainte, fixe un cadre avec lequel on peut évidemment jouer. On ne peut détacher l’analyse des corpus numériques des caractéristiques des plateformes qui hébergent ces formes d’écrits. Ces plateformes relèvent de modèles économiques essentiellement construits autour de la notion d’audience : la question de l’attention et de la notoriété y sont centrales (Kessous, Mellet et Zouinar, 2010) pour comprendre les mécanismes à l’œuvre. Il s’agit donc d’inclure dans l’analyse les caractéristiques du dispositif socio-technique qui sous-tend l’activité d’écriture et de garder en tête le modèle capitaliste qui structure l’activité.
18Deuxièmement, il s’agit d’une écriture d’assemblage ou écriture mosaïque (Beaudouin, 2019) à deux niveaux. Au niveau des publications, il ne s’agit plus seulement de textes, mais d’écriture qui agence textes, image, son, vidéo, avec un rôle de plus en plus central dévolu à l’image fixe ou animée. La forme d’une entrée de journal intime au tournant des années 2010, telle qu’elle apparaissait dans le réseau des écrivains sur le web, comprenait : un titre, une date, une photo, un texte. La recette de cuisine sur Instagram est aujourd’hui composée d’une séquence d’images (série de photo ou vidéo) avec l’ajout des ingrédients et les étapes de composition en commentaire, accompagné de tout un ensemble de hashtags. Au niveau d’organisation supérieure, on a des systèmes d’assemblage de textes comme le site personnel, le blog, la chaine YouTube, le compte Instagram, qui définissent une structure d’accueil et de mise en scène des différents contenus. Il faut pouvoir analyser la structure mosaïque des textes mais aussi celle des agencements de textes, la méta-structure. Si nous disposons d’une longue tradition pour l’analyse des textes, nous sommes moins équipés pour faire face à l’analyse de ces objets multimédias, dont chaque composante devrait pourvoir être analysée ainsi que les modes d’articulation entre ces médias.
19Troisièmement, c’est une écriture de la référence et du lien qui inscrit le texte dans un réseau de relations : lien vers d’autres textes (liens hypertextes), liens vers des personnes (adresses personnalisées), liens vers des thèmes (hashtag). Comme l’écrivait Roger Chartier, pour les auteurs, la mutation liée à la textualité électronique permet de s’affranchir de la linéarité propre à l’écrit : « le monde du numérique peut opposer de nouvelles propositions qui sont celles de logiques éclatées par le jeu du lien, de logiques simultanées, faisant apparaître sur une même surface, en même temps, des éléments distincts et, par ce fait, une logique relationnelle d’un ordre nouveau par rapport à la logique déductive » (Chartier, 2001). Et cela constitue une transformation épistémologique majeure. Ces nouvelles formes d’écriture nous invitent à avoir une approche relationnelle des textes, qui prend en compte le tissu des relations qui se tissent entre les fragments de textes.
20Quatrièmement, c’est une écriture qui intègre la réception (audience, avis, commentaires…) alors que le processus des industries culturelles a conduit à séparer la réception de la production, la lecture de l’écriture. Cavallo et Chartier rappelaient dans leur Histoire de la lecture qu’une des contraintes levées par les textes électroniques, est
celle qui limite étroitement les possibles interventions du lecteur dans le livre. […] La distinction immédiatement visible dans le livre imprimé entre l’écriture et la lecture, entre l’auteur du texte et le lecteur du livre, s’efface au profit d’une réalité différente : le lecteur devant l’écran devient un des acteurs d’une écriture à plusieurs mains, ou à tout le moins, il se trouve en position de constituer un texte nouveau avec des fragments librement découpés et assemblés » (Cavallo et Chartier, 1997, p. 39).
21Dans une version moins créative, on voit associés à chaque publication des commentaires, des appréciations (like, share…), des compteurs, soit autant d’indices de la réception et pour les spécialistes du marketing numérique de l’engagement des consommateurs (Bastard, 2015). L’analyse de corpus doit-elle intégrer la réception ?
22Enfin, il s’agit d’une écriture en mouvement, en transformation constante, qui ne bénéficie pas de la clôture que constitue l’acte d’édition et de publication en objet livre. Les écrits se transforment au fil du temps par expansion, retraits, modifications, réorganisations, ce qui pose des questions de fond pour l’archivage. Quel état des écrits doit-on préserver ? Les acteurs de l’archivage du web ont résolu pratiquement le problème en faisant des collectes à dates régulières, mais pour l’analyse le problème reste entier : comment analyser la dynamique de ces œuvres ouvertes en reconfiguration constante ?
Constituer, archiver, analyser des corpus numériques
23Comme nous venons de le voir, les textes numériques présentent des caractéristiques qui jouent sur les manières de les analyser. Inscrits dans des dispositifs socio-techniques, multimédias, réticulaires, intégrant la réception et ouverts, ils ne peuvent être traités comme des corpus classiques. En m’appuyant sur deux recherches, je montrerai les problèmes pratiques que posent la constitution, l’archivage et l’analyse de ces corpus nativement numériques. La première étude date du début des années 2010 et porte sur un réseau d’écrivains qui animent des sites web en ligne ; la seconde réalisée dans le contexte du Centenaire (2013-2018), explore les activités d’écriture des personnes qui s’occupent de préserver la mémoire de la Grande Guerre en ligne. Dans les deux cas, il s’agit d’identifier les activités d’écriture en ligne de personnes qui s’inscrivent dans des réseaux en dehors des cadres institutionnels. On peut à première vue les considérer comme appartenant à la catégorie des amateurs, ou de pro-am (des amateurs qui ont des pratiques qui les rapprochent de celles des professionnels) (Flichy, 2010 ; Severo, 2021), même si ces milieux se caractérisent par une grande diversité des engagements, certains ayant une reconnaissance institutionnelle, d’autres étant en voie de professionnalisation tandis que la majorité reste dans une posture d’amateur. Dans les deux cas, nous avons veillé à situer et caractériser ces pratiques en ligne par rapport à des pratiques plus traditionnelles. Ainsi pour les écrivains, l’objectif était aussi d’identifier les différentes manières de se rendre visible en ligne des écrivains.
Constituer et délimiter un corpus
24Pour délimiter un corpus issu du web, deux manières de faire sont utilisées qui tiennent à l’architecture du web. Soit on utilise un moteur de recherche et des mots-clefs pour identifier des documents qui peuvent relever du corpus que l’on cherche à constituer, soit on explore à partir de sites « noyaux » tous les sites cités pour repérer ceux qui relèvent de la thématique recherchée. En pratique les deux méthodes sont en général combinées. Le problème principal tient à la délimitation du corpus : quelles procédures mettre en place pour découper dans un tissu de sites reliés entre eux, ceux qui vont faire partie du corpus et ceux qui vont être exclus? Les deux recherches qui nous servent de fil rouge ont adopté des stratégies différentes : la première relève du bricolage avec constitution pas à pas du corpus ; la seconde délègue à une équipe de professionnels l’élaboration du corpus et définit une démarche beaucoup plus institutionalisée.
25Pour l’enquête sur les réseaux d’écrivains, comme point de départ ont été utilisés quelques sites de référence déjà identifiés comme centraux dans le monde des écrivains en ligne (comme remue.net, tierslivre.net, publie.net). À partir de ces sites, en allant de lien en lien avec l’outil alors utilisé (Navicrawler développé par Mathieu Jacomy et son équipe (Jacomy et al., 2014)), un premier état du corpus a été constitué avec adresses et liens. Mais comme il s’agissait de cartographier la présence du monde littéraire en ligne, pour pouvoir comparer différentes manières d’investir l’espace numérique, des entrées institutionnelles ont été retenues pour accéder à d’autres sites d’auteur·ices. Ainsi la Maison des écrivains pointe vers un grand nombre de sites d’écrivain.es qui ne se servent du web que comme site vitrine, sans organiser ou participer à des réseaux de relations avec d’autres écrivains en ligne. Avec une heuristique très manuelle, chaque fois qu’un nouveau site était identifié à partir d’un des noyaux, la décision était prise de l’intégrer ou non au corpus.
26Évidemment, la question des frontières est ici particulièrement sensible : à partir de quand accepte-t-on de considérer qu’un site d’auteur·ice fait partie du corpus ? Parce qu’iel se revendique auteur·ice ? parce que d’autres le ou la citent comme telle ? En avançant pas à pas dans la constitution du corpus, les critères de sélection ont pu évoluer sans même s’en rendre compte, car cette navigation de lien en lien ne présupposait pas la définition a priori de critères. L’absence de catalogue, l’incertitude sur les indexations par les moteurs et la fragilité de la navigation de lien en lien font qu’on ressent une grande incertitude face au corpus, avec un sentiment d’incomplétude tout en sachant qu’il n’est guère possible de faire mieux. La qualification manuelle des adresses identifiées (est-ce un site d’auteur, d’éditeur, de revue, d’institution culturelle ?) a été un moyen de contrôler les contours du corpus.
27Pour les sites liés à la Grande Guerre, la situation a été très différente, puisque je me suis appuyée sur un corpus établi par la BnF. Au moment du Centenaire de la Grande Guerre, la BnF et ses partenaires ont décidé d’archiver les sites liés à l’événement, soit de constituer une collecte dédiée, avec des sauvegardes à dates régulières pendant les années de commémoration. Une équipe de conservateur ices, qui se réunissait régulièrement, a établi la liste des sites qui devaient être archivés et ce travail d’identification a été mis à jour régulièrement pour repérer les nouveaux sites qui apparaissaient pendant la période (Sandras et Stirling, 2019). L’analyse a donc porté sur un corpus délimité par une autre équipe. Elle définit une nouvelle forme de collaboration entre le monde des bibliothèques et celui de la recherche, les chercheurs bénéficiant ainsi de l’expertise documentaire des conservateur ices de bibliothèque pour établir le corpus.
28La délimitation du corpus se heurte également à un problème de taille, celui de la privatisation croissante des espaces numériques avec la plateformisation du web. De plus en plus d’espaces demandent une authentification ou rendent l’accès aux contenus difficiles. Chaque réseau social a ses propres logiques de fonctionnement auxquelles les méthodes d’archivage s’adaptent plus ou moins bien. Si Twitter est le réseau social le plus étudié, ce n’est pas parce qu’il serait le plus utilisé ou le plus intéressant, mais simplement parce qu’il a offert depuis le début aux chercheurs une API pour pouvoir archiver des données de la plateforme. Inversement, la plateforme Facebook est sous-étudiée car la collecte des données y est particulièrement complexe. Elle est principalement analysée par des sociologues internes à l’entreprise. Dans ce paysage fermé, l’enquête Algopol sur les usages de Facebook, menée par une équipe de chercheurs en France, a constitué une exception (Bastard et al., 2017). Les contraintes d’accès aux plateformes limitent les possibilités de constitution des corpus, alors même que l’essentiel de l’activité en ligne s’est déplacé sur ces plateformes.
Archiver un corpus
29Comme nous l’avons vu la délimitation du corpus pose en soi toute une série de problèmes. Il faut pouvoir identifier, repérer les espaces de publication pertinents. Ensuite vient la phase de l’archivage, car il est difficile de travailler sur du web vivant tant il est soumis à un rythme d’évolution dynamique.
30Dès la fin des années 1990, la fondation Internet Archive s’est constituée avec le projet de préserver les contenus du web au niveau mondial, le projet s’est solidifié avec le lancement de la WaybackMachine en 2001 qui permet de retrouver un site donné dans ses versions antérieures. Cet effort d’archivage s’inscrit dans la tradition des pionniers du web soucieux de garder les traces de leur activité (Musiani et Schafer, 2017). La question de l’archivage du web s’est transformée en question politique, quand les États ont confié à leurs institutions culturelles la charge de préserver le patrimoine numérique. Pour la France, la loi DADVSI de 2006 charge l’INA, la BnF et le CNC d’archiver les productions numériques.
31En tant que chercheurs sur le numérique, on n’a pas attendu la législation pour procéder à des sauvegardes de corpus, avec une conscience aiguë de leur fragilité. Mais malheureusement, l’expérience m’a montrée qu’en dépit du soin apporté à ces sauvegardes, vingt ans plus tard, elles sont toutes quasiment inutilisables : les supports de sauvegarde ne sont plus lisibles (les prises de connexion ont changé, les lecteurs externes ne marchent plus…), et quand l’archive est accessible, les navigateurs ont tellement évolué qu’ils ne sont plus capables de rejouer le site tel qu’il était dans le passé. En bref, les sauvegardes « amateur » sont un désastre pour la recherche. En revanche, l’utilisation des archives du web, en dépit des freins juridiques (les archives du web ne peuvent être consultées et traitées qu’intra muros), représentent une opportunité exceptionnelle pour la recherche. En effet, les institutions en charge de l’archivage du web ont réfléchi collectivement aux manières d’archiver et de donner à voir les archives en développant et partageant des outils pour le faire (en particulier dans la communauté IIPC, International Internet Preservation Consortium). Comme le rappelle Emmanuelle Bermes, en retraçant l’histoire de la construction d’un patrimoine numérique à la BnF, l’idéal d’une archive mondiale a été abandonnée au bénéfice d’archives nationales, mais le souci d’interopérabilité entre les solutions a été maintenu (Bermès, 2020).
32Le rapport complexe entre l’archive et le document consulté a fait l’objet de réflexions théoriques : « le document consulté n’est pas le document archivé, mais un document reconstruit à partir des contenus archivés » (Bachimont, 2010). Partant d’une réflexion approfondie sur les caractéristiques du média1, Bruno Bachimont propose un cadre d’analyse qui traite de front les trois volets : « la captation des contenus du web, l’organisation et l’indexation de la mémoire ainsi obtenue ; la consultation de la mémoire archivée et organisée » qui doivent être articulés et posent un certain nombre de questions : comment organiser la périodicité de la captation selon les sites ? comment organiser la mémoire du réseau en tenant compte de l’organisation hypertextuelle et de sa stratification temporelle ? Comment organiser la visualisation de contenus aussi hétérogènes ? (Bachimont, 2004).
33L’outil Navicrawler utilisé pour explorer le réseau des écrivains en ligne ne permettait de sauvegarder que les URL des sites et les liens vers d’autres sites, sans aucune sauvegarde du contenu. Une fois le corpus constitué, il était nécessaire de revenir au web vivant pour examiner les sites, avec les risques importants de décalage entre le site tel qu’il était au moment où il avait été analysé et tel qu’il est au moment de l’exploration ethnographique.
34En revanche, sur le corpus Grande Guerre, l’archive porte sur le contenu complet du site en fonction de la profondeur définie pour l’archivage. Les techniques d’archivages employées garantissent une lisibilité du corpus à long terme et donc l’établissement d’une archive pérenne.
35Outre les questions juridiques, les archives du web présentent une technicité qui rend leur accès particulièrement complexe pour des chercheurs en sciences sociales, ce qui constitue une indéniable barrière à l’entrée. Les institutions culturelles mettent en place des laboratoires de soutien aux chercheur.es afin de démocratiser les usages de ces ressources, en offrant des formations, des outils ou des budgets d’accompagnement.
Analyser
36Comme nous l’avons vu, les corpus numériques issus du web, délimités et archivés, doivent permettre des explorations qui rendent compte des contenus, de l’organisation hypertextuelle et multimédia, de la dynamique temporelle… Les défis pour l’analyse sont nombreux. Dans un panorama des recherches contemporaines, Cointet et Parasie ont montré ce que le « big data fait à l’analyse sociologique des textes » (Cointet et Parasie, 2018) et ont ensuite dirigé un numéro de la revue Réseaux « Enquêter à partir des traces du web » (Cointet et Parasie, 2019) montrant comment l’analyse des corpus textuels vient éclairer des questionnements de la sociologie et des sciences connexes. Ici je cherche à montrer comment la tradition de la linguistique de corpus se trouve renouvelée par les caractéristiques spécifiques des corpus issus du web. Ce faisant via un autre angle, je croise des éléments de leur analyse.
37Dans cette dernière section, je souhaite défendre trois principes exigeants et pas toujours faciles à mettre en œuvre pour l’analyse des corpus du web. Le premier invite à mettre en place des méthodes qui permettent de combiner des approches qui portent sur les textes et des approches qui explorent la structure réticulaire des documents, en bref tenir ensemble la dimension textuelle et hypertextuelle ; le deuxième invite à combiner des approches à différentes échelles, qualitatives et quantitatives, en bref articuler le close et le distant reading ; le troisième à articuler l’analyse des corpus avec des enquêtes auprès des producteurs de contenus, autrement dit combiner analyse des textes et enquête sociologique.
38Face à des corpus du web de plus en plus volumineux, le recours à des méthodes quantitatives, qualifiées de Digital Methods est devenu nécessaire. Deux grandes catégories de méthodes sont utilisées pour traiter les big data : d’une part, les méthodes de la fouille de texte pour l’analyse des contenus (analyse thématique, analyse de « sentiment », analyse formelle), d’autre part les méthodes d’analyse de réseaux qui traitent des relations entre documents. Ces méthodes relèvent de deux traditions épistémologiques différentes, l’une issue de l’analyse de discours, l’autre de la tradition de l’analyse de graphe et de sa branche appliquée : l’analyse des réseaux. Les outils qui permettent de combiner les deux approches sont rares, il est donc du ressort des chercheur es de « bricoler » pour définir une articulation de méthodes qui fasse sens par rapport au questionnement.
39Pour la recherche sur les auteurs numériques en ligne, je ne disposais « que » du réseau des relations entre les sites, en raison de l’outil utilisé qui, venant de la tradition de l’analyse de réseau, ne donnait pas accès au contenu des sites mais à une représentation des relations entre sites grâce aux liens hypertextuels. En revanche, en travaillant en partenariat avec la BnF et le service des archives du web, l’accès à la collecte Grande Guerre nous a permis d’articuler les deux approches (contenus et relations). D’une part, en cartographiant les relations entre les sites (approche graphes et réseaux), nous avons pu montrer la présence d’un réseau dense d’amateurs, auteurs de sites dédiés à la mémoire de la guerre et au cœur de ce réseau, l’existence d’un forum de discussion très actif sur lequel se retrouvaient les amateurs. D’autre part, pour donner sens aux 400 000 messages du forum et comprendre ce qui se passait dedans, nous avons analysé le corpus constitué des messages du forum (approche contenu) pour faire émerger les thématiques, puis analyser quels auteurs étaient les plus impliqués dans chaque catégorie. Ainsi, si la moitié des échanges porte sur l’entraide dans les recherches généalogiques (« comment retrouver où était mon arrière-grand-père pendant la guerre ? »), 20% des messages portent sur les actualités commémoratives, 14% sur les échanges autour des tombes et cimetières, 9% correspondent à des échanges entre collectionneurs tandis que le reste des messages rassemble des spécialistes pointus de la marine. La décision d’explorer le contenu textuel du forum s’est imposée à l’examen de sa place très singulière dans la structure du graphe : si l’examen qualitatif, « à la main », des sites du réseau des amateurs a permis assez rapidement d’identifier leur nature (mémoriaux en ligne dédiés à un régiment particulier, qui rendent hommage aux hommes et aux batailles), le volume des échanges dans le forum rendait toute lecture « humaine » impossible et le recours aux méthodes quantitatives adaptées pour construire une vision globale.
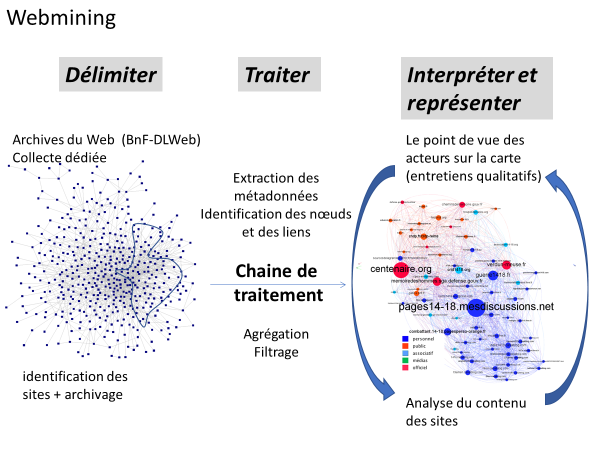

Figure . Approche réseau (webmining) et approche contenu (textmining) sur le Web de la Grande Guerre
40Le deuxième principe qu’il nous parait nécessaire de tenir est celui de l’articulation entre des approches quantitatives et qualitatives, en faisant varier la focale. Dans un essai vivifiant, Boyd et Crawford soulignent les risques liés au big data, alors qu’ils font l’objet d’un fort engouement2. Tout en partageant le point de vue des autrices, il me semble qu’une bonne stratégie consiste à articuler ces approches quantitatives sur des grands corpus avec des approches ethnographiques et qualitatives. Parce qu’elles sont compréhensives ces dernières permettent de donner du sens à des résultats quantitatifs, voire de faire émerger des hypothèses qui pourront être testées à grande échelle. Elles permettent de mettre au défi les résultats produits par les traitements de type big data : ce que l’on observe au niveau macro fait-il sens au niveau micro ?
41Dans le cadre des deux recherches, une partie très conséquente du travail a consisté à aller explorer pas à pas les différents sites du réseau afin de comprendre par qui ils étaient animés, comment étaient organisés les contenus, quels éléments étaient agencés dans les sites. C’est cet examen de proximité, close reading, qui a permis de montrer l’opposition entre les écrivains qui utilisent le web comme une simple vitrine promotionnelle et ceux qui l’utilisent comme un atelier d’écriture. De même pour la Grande Guerre, cette lecture de près a permis d’identifier les traits caractéristiques des sites régimentaires (reconstituer la biographie des soldats, retracer la séquence des batailles, montrer ses liens avec les autres sites régimentaires) et les motivations affichées par leurs auteurs (éviter aux soldats la seconde mort de l’oubli, garder la mémoire pour éviter que l’histoire ne se répète…).
42Enfin, le troisième principe consiste à éclairer les analyses de corpus avec une enquête sociologique auprès des auteur·ices ou producteur ices de contenu. Ces écrits qui laissent des traces résultent de pratiques sociales qui engagent de nombreuses personnes. L’enquête à base d’entretiens a plusieurs visées. Elle permet d’une part d’accéder au sens que l’auteur·ice accorde à son geste d’écriture (pourquoi animer un site d’écriture littéraire ou un mémorial en ligne ? ). Ensuite elle donne à voir les coulisses de l’écriture : quel travail de recherche, quels échanges en ligne et hors ligne sous-tendent ce travail de publication. Enfin, elle permet de faire évaluer par les acteurs eux-mêmes les résultats produits par les méthodes quantitatives.
43Dans la recherche sur la Grande Guerre, les entretiens m’ont permis de découvrir la face non publique des échanges : ainsi j’ai appris que beaucoup d’échanges quittaient le forum pour basculer en conversation privée (par exemple quand quelqu’un demande une photographie de la tombe de son ancêtre, celle-ci, une fois réalisée par un des membres du réseau des photographes de tombes, n’est jamais envoyée dans l’espace public mais transmise par les canaux privés) et j’ai eu connaissance de toutes les rencontres hors ligne des membres du réseau (pour rénover un monument, pour faire une enquête sur le terrain…). Le monde numérique ne reflète qu’une partie de l’activité des acteur ices. Les entretiens m’ont donné accès aux motivations et à la signification que revêtait pour les auteur·ices ce travail de recherche, d’écriture et de publication. Enfin, ils ont été l’occasion d’une mise à l’épreuve des résultats de l’analyse du réseau ou de l’analyse du forum. Ainsi face à la carte du réseau de la Grande Guerre sur le web, les enquêté.es reconnaissaient les différentes zones de la carte (la zone des sites institutionnels, celle des sites amateurs, la zone frontière des sites institutionnels très utilisés par les amateurs, comme Mémoire des hommes ou Gallica), mais ils voyaient aussi les manques sur la carte, par exemple l’absence des sites hors France essentiels dans leur activité comme celui de la Croix-Rouge qui recense tous les prisonniers de guerre, ou les sites surgonflés (qui paraissent importants par leurs réseaux de liens mais ne le sont pas du fait de la pauvreté de leurs contenus). L’interprétation de la carte se fait donc en coopération avec les acteurs.
44Traiter le contenu et les relations, changer les échelles d’analyse (macro et mico), enquêter sur les textes et sur les producteur·trices, telles sont les recommandations qui nous permettent de dépasser les limites des approches de type big data.
*
45À l’issue de ce parcours, nous avons montré que l’essor du web a conduit à l’émergence de nouvelles formes d’écritures en ligne qui se distinguent des formes antérieures : elles sont encastrées dans des dispositifs socio-techniques soumis au rythme accéléré de l’innovation, elles sont multimédia, réticulaires, en conversation avec le public et sont soumises à une dynamique de transformation intense. Les caractéristiques de ces écritures numériques transforment les tâches de délimitation, d’archivage et d’analyse de corpus. Ainsi, le champ des Humanities Computing, qui s’était constitué autour de l’analyse de corpus textuels, s’est ainsi vu transformé en un champ au périmètre plus large, celui des Digital Humanities.
46Alors que les méthodes d’analyse de corpus reposaient principalement sur l’analyse de texte, avec ces corpus nativement numériques, deux grandes catégories de méthodes sont mobilisées pour les corpus nativement numériques, celles qui portent sur le contenu, et celles qui portent sur les relations (pour rendre compte de la structure réticulaire). Les progrès spectaculaires dans l’analyse d’image devraient permettre de traiter la dimension visuelle des corpus. Enfin, si la dimension temporelle de l’analyse des sites a fait l’objet d’explorations, de nombreux verrous sont encore à lever pour rendre compte de manière simple des évolutions. Il en est de même pour l’inclusion de la réception dans l’analyse.
47En bref, beaucoup de briques permettent de traiter certaines dimensions des corpus (le texte, les liens, les images, le temps…) mais peu d’outils permettent de traiter ensemble ces dimensions. De nouvelles frontières à dépasser se dessinent pour l’analyse des corpus, avec des techniques performantes à base d’intelligence artificielles.
48Sans céder à la fascination pour le progrès technique, je plaide pour trois principes : celui de l’articulation des méthodes (réseaux, contenu textuel, images, temps) ; celui de l’association entre traitement quantitatif de masse avec des approches à grain fin (analyse sémiotique, stylistique, ethnographique) et celui de la nécessaire combinaison entre analyse de corpus et enquête sociologique dans un souci de rapprocher les manières de faire des « humanités » et des sciences sociales dans un souci de meilleure compréhension des phénomènes.